|
I am an Associate Professor in the Department of Computer Science at National Yang Ming Chiao Tung University. I work on image/video processing, computer vision, and computational photography, particularly on essential problems requiring machine learning with insights from geometry and domain-specific knowledge. Prior to joining NYCU, I was a Research Scientist Intern at Meta Reality Labs Research and a senior software engineer at MediaTek Inc. I received my PhD from NTU, CSIE in 2022, where I was a member of CMLab. I received the 教育部玉山青年學者, 國科會 2030 新秀學者, Google Research Scholar Award, 李國鼎青年研究獎, 資訊年輕學者卓越貢獻獎, and CVPR 2024 Outstanding Reviewer award. Dear prospective students: I am looking for undergraduate / master's / Ph.D. / postdoc students to join my group. If you are interested in working with me and want to conduct research in image processing, computer vision, and machine learning, don't hesitate to contact me directly with your CV and transcripts. Email / CV / Google Scholar / Facebook / Instagram / Github / YouTube |
 For those who personally know me, that might be thinking: Who is this guy?
For those who personally know me, that might be thinking: Who is this guy? Hover over to see how I usually look like before a paper submission deadline. Meet my cats: 虎皮捲 and 雞蛋糕! |
.svg.png)

|











赵祯俊 
端木竣偉 
范丞德 
李杰穎 
劉珆睿 
簡浩任 
李沅罡 
楊承諭 
李家銘 
徐聖旂 
林宇凡 
黃怡川 
黃正輝 
呂承祐 
蘇智海 
林晉暘 
林佳城 
許皓翔 
陳映寰 
張欀齡 
鄭淮薰 
柯柏旭 
王皓平 
戚維凌 
俞柏帆 
黃靖恩 
張維程 
司徒立中 吳定霖 
張智堯 
陳光齊 
何義翔 
李明謙 孫揚喆 
李宗諺 楊宗儒 
朱驛庭 
徐和 
謝侑哲 
鄭名翔 
葉家蓁 
徐顥 
李佑軒 
周廷威 陳芝瑄 
曾士珍 
楊睿軒 
陳璽安 
張盛瑋 
劉彥廷 
彭程 曾煥宗 
徐少晞 
張芷瑜 
陳孟楷 陳信安 
林采儀 
鄭安喆 
陳柏予 
張恩睿 
蔡雨翰 
黃立達 
吳柏志 
賴香伊 
林喬安 
鄭伯俞 陳俊瑋 林奕杰 羅宇呈 郭玠甫 葉柔昀 
鄭又豪 丁祐承 
謝明翰 
施惟智 
朱劭璿 
吳秉宸 陳士弘 陳昱佑 
陳凱昕 吳俊宏 
葉長瀚 
陳楊融 
吳中赫 
林佑庭 
黃亭幃 
嚴士函 
陳霆軒 
張宸瑋 
胡智堯 
蔡聿瑋 蔡昀錚 
邢捷 
葉孟昀 
陳捷文 
蔡師睿 林揚森 |
|
|
|
|
|

|
Siang-Ling Zhang, Huai-Hsun Cheng, Tsung-Ju Yang, Yu-Lun Liu ECCV, 2026 
project page / arXiv / code This paper proposes a cross-space dual-branch denoising process, and introduces a view-conditioned texture synthesis module that projects and aggregates view-specific 2D diffusion priors onto the fused geometry. |

|
Cheng-You Lu, Yi-Shan Hung, Wei-Ling Chi, Hao-Ping Wang, Charlie Li-Ting Tsai, Yu-Cheng Chang, Yu-Lun Liu, Thomas Do, Chin-Teng Lin ECCV, 2026
arXiv DF3DV-1K is introduced, a large-scale real-world dataset comprising 1,048 scenes, each providing clean and cluttered image sets for benchmarking, and an application of DF3DV-1K is demonstrated by fine-tuning a diffusion-based 2D enhancer to improve radiance field methods. |
 
|
Yuan-Kang Lee, Kuan-Lin Chen, Chia-Che Chang, Yu-Lun Liu ECCV, 2026
project page / arXiv / code / dataset This work presents RL-AWB, a novel framework combining statistical methods with deep reinforcement learning for nighttime white balance, the first deep reinforcement learning approach for color constancy that leverages the statistical algorithm as its core. |

|
Hau-Shiang Shiu, Chin-Yang Lin, Zhixiang Wang, Chi-Wei Hsiao, Po-Fan Yu, Yu-Chih Chen, Yu-Lun Liu ECCV, 2026 (Oral Presentation)
project page / arXiv / code Stream-DiffVSR achieves the lowest latency reported for diffusion-based VSR, reducing initial delay from over 4600 seconds to 0.328 seconds, thereby making it the first diffusion VSR method suitable for low-latency online deployment. |

|
Jie-Ying Lee, Yi-Ruei Liu, Shr-Ruei Tsai, Wei-Cheng Chang, Chung-Ho Wu, Jiewen Chan, Zhenjun Zhao, Chieh Hubert Lin, Yu-Lun Liu ECCV, 2026
project page / arXiv / code This paper proposes Skyfall-GS, the first city-block scale 3D scene creation framework without costly 3D annotations, also featuring real-time, immersive 3D exploration, and tailor a curriculum-driven iterative refinement strategy to progressively enhance geometric completeness and photorealistic textures. |

|
Yi-Ruei Liu, Jie-Ying Lee, Zheng-Hui Huang, Yu-Lun Liu†, Chih-Hao Lin† arXiv, 2026
project page / arXiv / code / dataset / results BRDFusion is presented, a unified framework that combines two complementary models for inverse and forward rendering, and recovers explicit, consistent scene properties with physical modeling and alleviates optimization ambiguity with generative priors. |

|
Cheng-Yu Yang, Shao-Yuan Lo, Yu-Lun Liu arXiv, 2026
arXiv / code Reroute is proposed, a training-free plug-in that replaces removal with recoverable routing that improves grounding under aggressive token reduction while maintaining general VQA performance and suggests that VLM token reduction should be viewed only as irreversible pruning, but also as recoverable routing. |

|
Cheng-De Fan, Chun-Wei Tuan Mu, Chen-Wei Chang, Chin-Yang Lin, Kun-Ru Wu, Yu-Chee Tseng, Yu-Lun Liu SIGGRAPH, 2026
project page / arXiv / code This work proposes LongE2V, a novel approach that leverages pre-trained video diffusion priors to jointly handle event-based video reconstruction, prediction, and frame interpolation, and introduces Autoregressive Unrolling and Adaptive Context Switching to mitigate temporal drift in extremely long sequences. |
 
|
Huai-Hsun Cheng, Siang-Ling Zhang, Yu-Lun Liu SIGGRAPH, 2026
project page / arXiv / code This work introduces Progressive Semantic Illusions, a novel vector sketching task where a single sketch undergoes a dramatic semantic transformation through the sequential addition of strokes, and presents Stroke of Surprise, a generative framework that optimizes vector strokes to satisfy distinct semantic interpretations at different drawing stages. |

|
Teng-Fang Hsiao, Bo-Kai Ruan, Yu-Lun Liu, Hong-Han Shuai SIGGRAPH, 2026
arXiv / code VecSet-Edit is proposed, the first pipeline that leverages the high-fidelity VecSet Large Reconstruction Model (LRM) as a backbone for mesh editing and introduces Mask-guided Token Seeding and Attention-aligned Token Gating strategies to precisely localize target regions using only 2D image conditions. |

|
Zheng-Hui Huang, Zhixiang Wang, Jiaming Tan, Ruihan Yu, Yidan Zhang, Bo Zheng, Yu-Lun Liu, Yung-Yu Chuang, Kaipeng Zhang arXiv, 2026
project page / arXiv / code / demo / video A large-scale, dynamic dataset curated from visually complex AAA games is introduced, enabling robust in-the-wild geometry and material decomposition, and facilitating high-fidelity G-buffer-guided video generation and a novel VLM-based assessment protocol measuring semantic, spatial, and temporal consistency. |
 
|
Zheng-Hui Huang, Zhixiang Wang, Yu-Lun Liu, Yung-Yu Chuang CVPR, 2026 project page / arXiv / code A diffusion model explicitly fine-tuned for single-image reflection separation is presented, leveraging generative diffusion priors for robust separation and incorporating a novel cross-layer self-attention mechanism for better feature disentanglement. |

|
Ting-Hsuan Chen*, Ying-Huan Chen*, Tao Tu, Jie-Ying Lee, Cho-Ying Wu, Fangzhou Lin, Hengyuan Zhang, David Paz, Xinyu Huang, Yuliang Guo†, Yu-Lun Liu†, Yue Wang†, Liu Ren CVPR, 2026 project page / arXiv Pantheon360: Taming Digital Twin Generation via 3D-Aware 360° Video Diffusion is introduced, a controllable 360° video generation framework that synthesizes high-fidelity videos from sparse 360° inputs that allows the diffusion model to focus on photorealistic texture refinement while the 3D Cache enforces global geometric consistency. |
 
|
Chia-Ming Lee, Yu-Fan Lin, Yu-Jou Hsiao, Jin-Hui Jiang, Yu-Lun Liu, Chih-Chung Hsu CVPR, 2026 project page / arXiv / code This work proposes PhaSR (Physically Aligned Shadow Removal), addressing this through dual-level prior alignment to enable robust performance from single-light shadows to multi-source ambient lighting where traditional methods fail under multi-source illumination. |
 
|
Chia-Ming Lee, Yu-Fan Lin, Jin-Hui Jiang, Yu-Jou Hsiao, Chih-Chung Hsu, Yu-Lun Liu CVPR, 2026 project page / arXiv / code ReflexSplit, a dual-stream framework with three key innovations that adaptively aggregates semantic priors, texture details, and decoder context across hierarchical depths, stabilizing gradient flow and maintaining feature consistency, is proposed. |

|
Jiewen Chan, Zhenjun Zhao, Yu-Lun Liu CVPR Findings, 2026 project page / arXiv / code This work proposes AdaGaR, a unified framework addressing both frequency adaptivity and temporal continuity in explicit dynamic scene modeling, and introduces Adaptive Gabor Representation, extending Gaussians through learnable frequency weights and adaptive energy compensation to balance detail capture and stability. |

|
Yi-Chuan Huang, Jiewen Chan, Hao-Jen Chien, Yu-Lun Liu CVPR, 2026 project page / arXiv / code Voxify3D is introduced, a differentiable two-stage framework bridging 3D mesh optimization with 2D pixel art supervision that addresses fundamental challenges: semantic preservation under extreme discretization, pixel-art aesthetics through volumetric rendering, and end-to-end discrete optimization. |

|
Jing-En Huang, I-Sheng Fang, Tzuhsuan Huang, Yu-Lun Liu, Chih-Yu Wang, Jun-Cheng Chen CVPR Findings, 2026 arXiv / code Gen-n-Val, a novel agentic data generation framework that leverages Layer Diffusion, a Large Language Model (LLM), and a Vision Large Language Model (VLLM) to produce high-quality and diverse instance masks and images for object detection and instance segmentation, has scalability in model capacity and dataset size. |

|
Yang-Che Sun, Cheng Sun, Chin-Yang Lin, Fu-En Yang, Min-Hung Chen, Yen-Yu Lin, Yu-Lun Liu arXiv, 2026
project page / arXiv / code (coming soon) / demo This work introduces 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2, and proposes a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. |
|
Hong-Xuan Yen, Chiamin Chen, Yanqing Wang, Yu-Lun Liu, Min Sun WACV, 2026 paper / supplement PS3 is introduced, an approach to generate 3D part proposals from multi-view 2D masks that outperforms baselines that rely on geometric over-segmentation in scene-scale open-vocabulary 3D part segmentation. |

|
Cheng-Yuan Ho, He-Bi Yang, Jui-Chiu Chiang, Yu-Lun Liu, Wen-Hsiao Peng WACV, 2026 project page / arXiv This work presents TED-4DGS, a temporally activated and embedding-based deformation scheme for rate-distortion-optimized 4DGS compression that unifies the strengths of both families and represents one of the first attempts to pursue a rate-distortion-optimized compression framework for dynamic 3DGS representations. |
 
|
Yo-Tin Lin, Su-Kai Chen, Hou-Ning Hu, Yen-Yu Lin, Yu-Lun Liu WACV, 2026 arXiv / code This work presents a training-free approach that enhances existing indirect and direct HDR reconstruction methods through diffusion-based inpainting that seamlessly integrates with existing HDR reconstruction techniques through an iterative compensation mechanism that ensures luminance coherence across multiple exposures. |

|
Hao-Jen Chien, Yi-Chuan Huang, Chung-Ho Wu, Wei-Lun Chao, Yu-Lun Liu WACV, 2026 project page / arXiv / code / dataset Splannequin is proposed, an architecture-agnostic regularization that detects two states of Gaussian primitives, hidden and defective, and applies temporal anchoring, resulting in markedly improved visual quality, enabling high-fidelity, user-selectable frozen-time renderings, validated by a 96% user preference. |
|
|
|

|
Yi-Chuan Huang, Hao-Jen Chien, Chin-Yang Lin, Ying-Huan Chen, Yu-Lun Liu arXiv, 2025
project page / arXiv / code / results GaMO (Geometry-aware Multi-view Outpainter), a framework that reformulates sparse-view reconstruction through multi-view outpainting with geometry-aware denoising strategies in a zero-shot manner without training is introduced. |

|
Chun-Wei Tuan Mu, Jia-Bin Huang, Yu-Lun Liu arXiv, 2025
project page / arXiv / code / video / demo Generative Refocusing is introduced, a two-step process that uses DeblurNet to recover all-in-focus images from various inputs and BokehNet for creating controllable bokeh, using EXIF metadata to capture real optical characteristics beyond what simulators can provide. |

|
Meng-Li Shih, Ying-Huan Chen, Yu-Lun Liu, Brian Curless SIGGRAPH Asia, 2025 project page / paper This work enhances the priors that drive Dynamic Gaussian Splatting, a fully automatic pipeline for dynamic scene reconstruction from casually captured monocular RGB videos that surpasses previous monocular dynamic scene reconstruction methods and delivers visibly superior renderings. |
 
|
Yang-Che Sun, Cheng Yu Yeo, Ernie Chu, Jun-Cheng Chen, Yu-Lun Liu NeurIPS, 2025 project page / arXiv / code This work replaces the representation of prior models from simple feature maps with Factorized Features to validate the potential for broad generalizability and further optimize the compression pipeline by leveraging the mergeable-basis property of the authors' Factorized Features, which consolidates shared structures on multi-frame compression. |

|
Li-Zhong Szu-Tu*, Ting-Lin Wu*, Chia-Jui Chang, He Syu, Yu-Lun Liu ICCV DataCV Workshop, 2025 project page / arXiv / code / dataset / results We introduce the largest open benchmark for building construction year prediction: the YearGuessr dataset, a collection of 55,546 building images with multi-modal attributes from 157 countries, annotated with continuous ordinal labels of their construction year (1001-2024), GPS data, and page-view counts as a proxy for popularity. |
 
|
Shr-Ruei Tsai, Wei-Cheng Chang, Jie-Ying Lee, Chih-Hai Su, Yu-Lun Liu ICCV, 2025 project page / arXiv / code / video / demo LightsOut, a diffusion-based outpainting framework tailored to enhance SIFR by reconstructing off-frame light sources by leveraging a multitask regression module and LoRA fine-tuned diffusion model to ensure realistic and physically consistent outpainting results. |
|
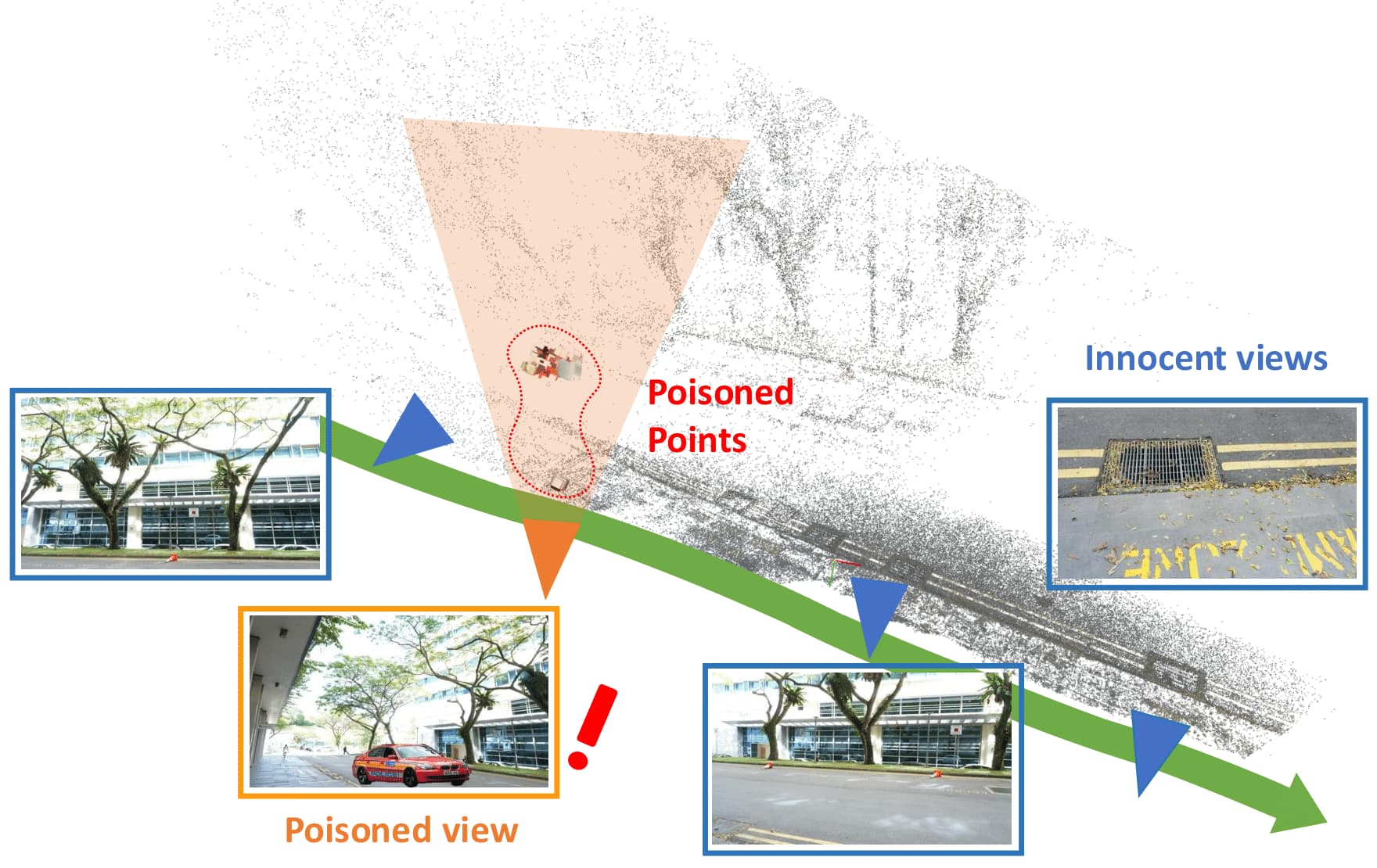
Bo-Hsu Ke, You-Zhe Xie, Yu-Lun Liu, Wei-Chen Chiu ICCV, 2025 project page / arXiv / code / results This work analyzes 3DGS robustness against image-level poisoning attacks and proposes a novel density-guided poisoning method that strategically injects Gaussian points into low-density regions identified via Kernel Density Estimation (KDE), embedding viewpoint-dependent illusory objects clearly visible from poisoned views while minimally affecting innocent views. |

|
Chin-Yang Lin, Cheng Sun, Fu-En Yang, Min-Hung Chen, Yen-Yu Lin, Yu-Lun Liu ICCV, 2025 project page / arXiv / code LongSplat is introduced, a robust unposed 3D Gaussian Splatting framework featuring a robust Pose Estimation Module leveraging learned 3D priors, and an efficient Octree Anchor Formation mechanism that converts dense point clouds into anchors based on spatial density. |
|
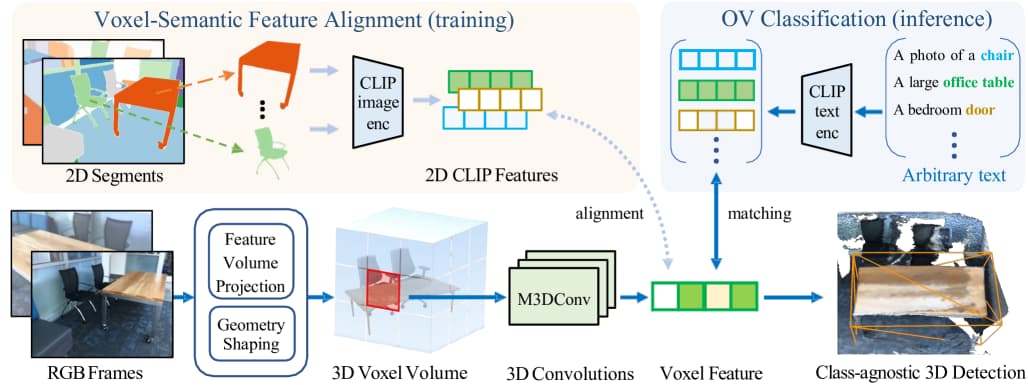
Peng-Hao Hsu, Ke Zhang, Fu-En Wang, Tao Tu, Ming-Feng Li, Yu-Lun Liu, Albert Y. C. Chen, Min Sun, Cheng-Hao Kuo ICCV, 2025 project page / arXiv OpenM3D, a novel open-vocabulary multi-view indoor 3D object detector trained without human annotations, is introduced and a 3D Pseudo Box Generation method using a graph embedding technique that combines 2D segments into coherent 3D structures is proposed. |

|
Chih Yao Hu*, Yang-Sen Lin*, Yuna Lee, Chih-Hai Su, Jie-Ying Lee, Shr-Ruei Tsai, Chin-Yang Lin, Kuan-Wen Chen, Tsung-Wei Ke, Yu-Lun Liu CoRL, 2025 project page / arXiv / code / video This work presents See, Point, Fly (SPF), a training-free aerial vision-and-language navigation (AVLN) framework built atop vision-language models (VLMs), to consider action prediction for AVLN as a 2D spatial grounding task. |
|
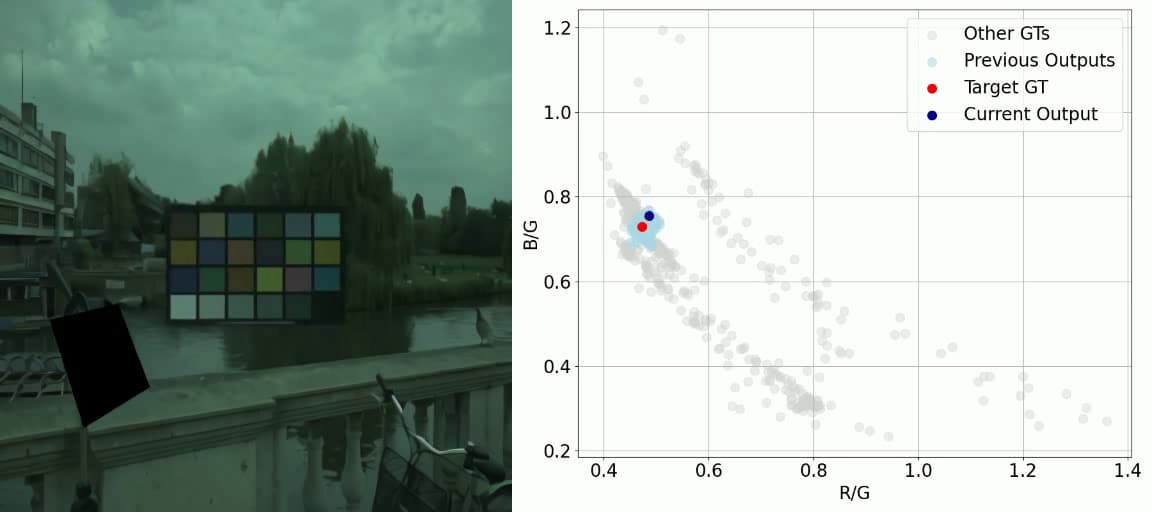
Chen-Wei Chang, Cheng-De Fan, Chia-Che Chang, Yi-Chen Lo, Yu-Chee Tseng, Jiun-Long Huang, Yu-Lun Liu CVPR, 2025 project page / arXiv / code / video GCC demonstrates superior robustness in cross-camera scenarios, achieving state-of-the-art worst-25% error rates and highlights the method's stability and generalization capability across different camera characteristics without requiring sensor-specific training, making it a versatile solution for real-world applications. |

|
Chung-Ho Wu*, Yang-Jung Chen*, Ying-Huan Chen, Jie-Ying Lee, Bo-Hsu Ke, Chun-Wei Tuan Mu, Yi-Chuan Huang, Chin-Yang Lin, Min-Hung Chen, Yen-Yu Lin, Yu-Lun Liu CVPR, 2025 project page / arXiv / code / data / video / results This work presents AuraFusion360, a novel reference-based method that enables high-quality object removal and hole filling in 3D scenes represented by Gaussian Splatting, and introduces 360-USID, the first comprehensive dataset for 360° unbounded scene inpainting with ground truth. |

|
Cheng-De Fan, Chen-Wei Chang, Yi-Ruei Liu, Jie-Ying Lee, Jiun-Long Huang, Yu-Chee Tseng, Yu-Lun Liu CVPR, 2025 project page / arXiv / code / video / results SpectroMotion, a novel approach that combines 3D Gaussian Splatting with physically-based rendering (PBR) and deformation fields to reconstruct dynamic specular scenes, outperforming state-of-the-art methods in rendering complex, dynamic, and specular scenes. |
|
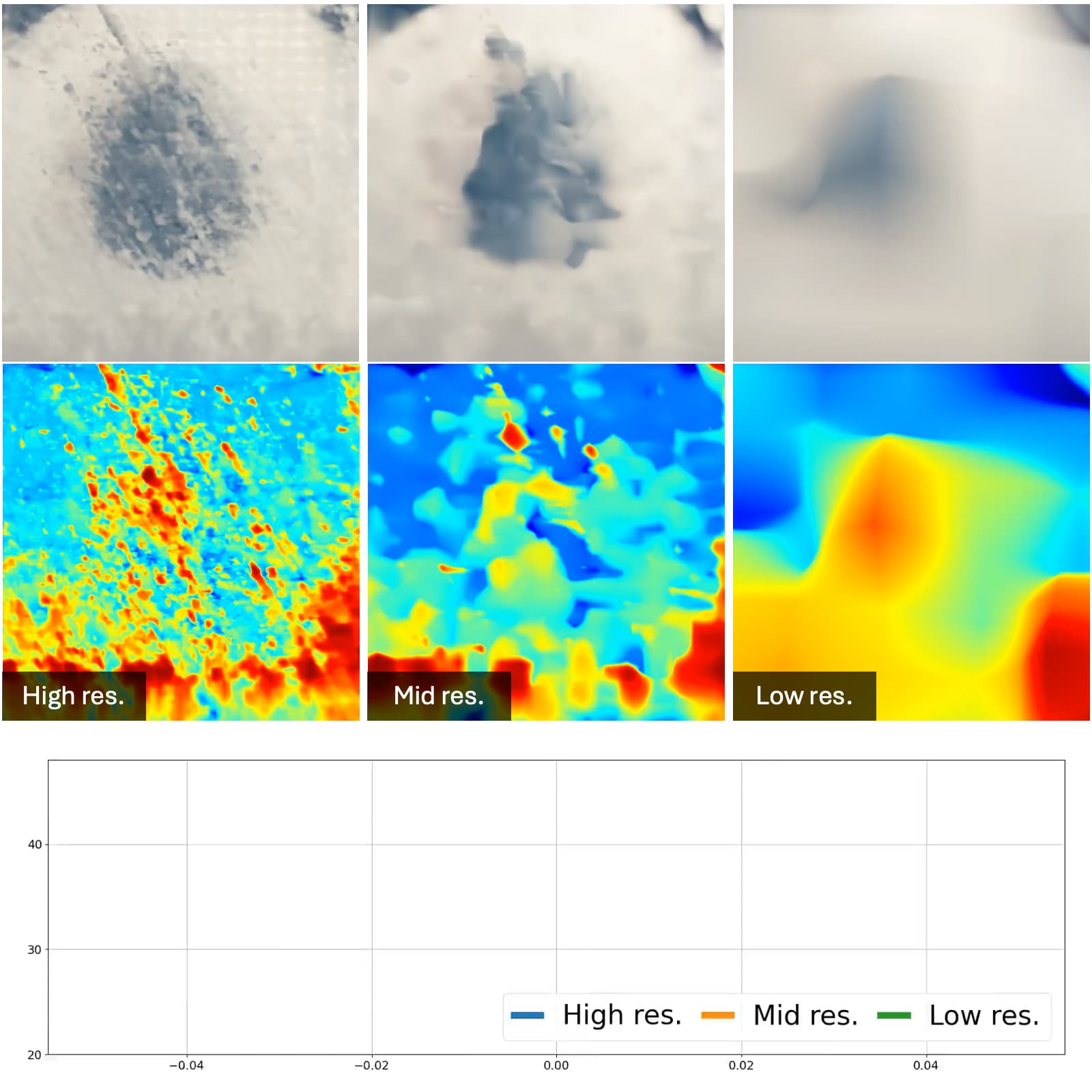
Chin-Yang Lin*, Chung-Ho Wu*, Chang-Han Yeh, Shih-Han Yen, Cheng Sun, Yu-Lun Liu† CVPR, 2025 project page / arXiv / code / video FrugalNeRF is introduced, a novel few-shot NeRF framework that leverages weight-sharing voxels across multiple scales to efficiently represent scene details and guides training without relying on externally learned priors, enabling full utilization of the training data. |
|
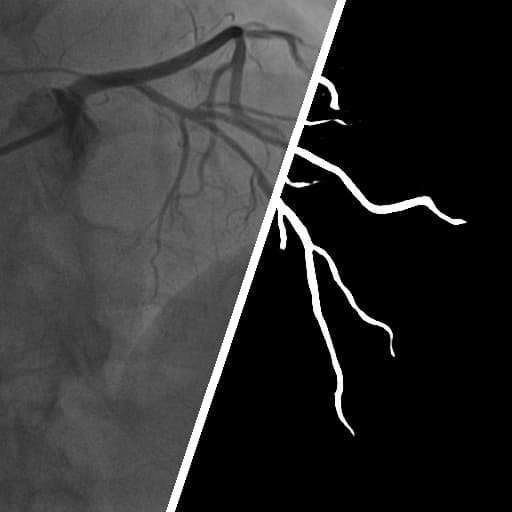
Chun-Hung Wu, Shih-Hong Chen, Chih-Yao Hu, Hsin-Yu Wu, Kai-Hsin Chen, Yu-You Chen, Chih-Hai Su, Chih-Kuo Lee, Yu-Lun Liu CVPR, 2025 project page / arXiv / code / dataset / colab Deformable Neural Vessel Representations is presented, an unsupervised approach for vessel segmentation in X-ray angiography videos without annotated ground truth that outperforms current state-of-the-art methods in vessel segmentation accuracy and generalization capability while maintaining temporal coherency. |
|
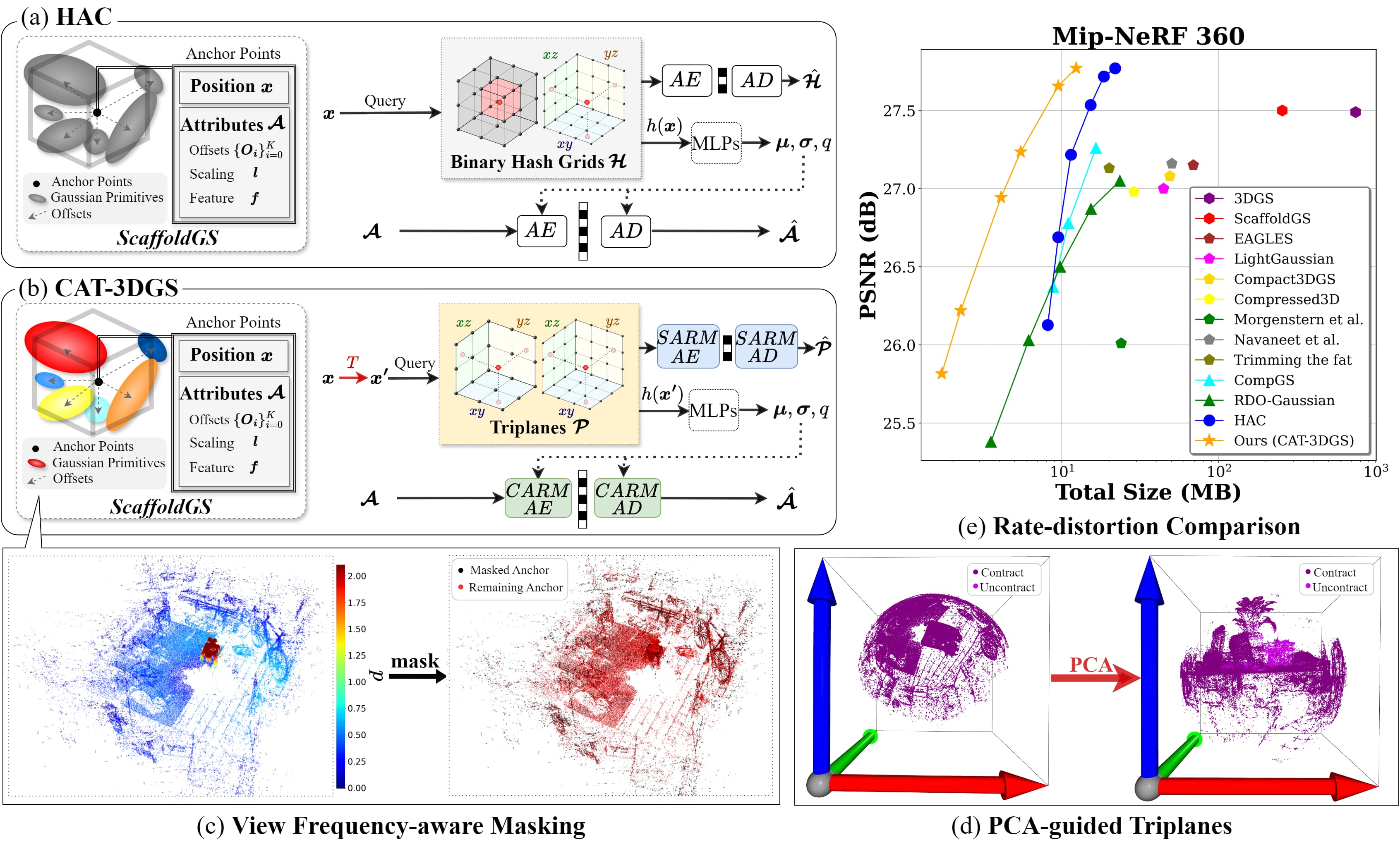
Yu-Ting Zhan*, Cheng-Yuan Ho*, Hebi Yang, Jui-Chiu Chiang, Yu-Lun Liu, Wen-Hsiao Peng ICLR, 2025 arXiv This work introduces a context-adaptive triplane approach to their rate-distortion-optimized 3DGS compression, which achieves the state-of-the-art compression performance on the commonly used real-world datasets. |
 
|
Hao-Yu Hou*, Chia-Chi Hsu*, Yu-Chen Huang*, Mu-Yi Shen*, Wei-Fang Sun, Cheng Sun, Chia-Che Chang, Yu-Lun Liu, Chun-Yi Lee ICASSP, 2025 paper In this study, we propose an uncertainty estimation approach to assist 3DGS in reconstructing 3D scenes and removing transients. |
|
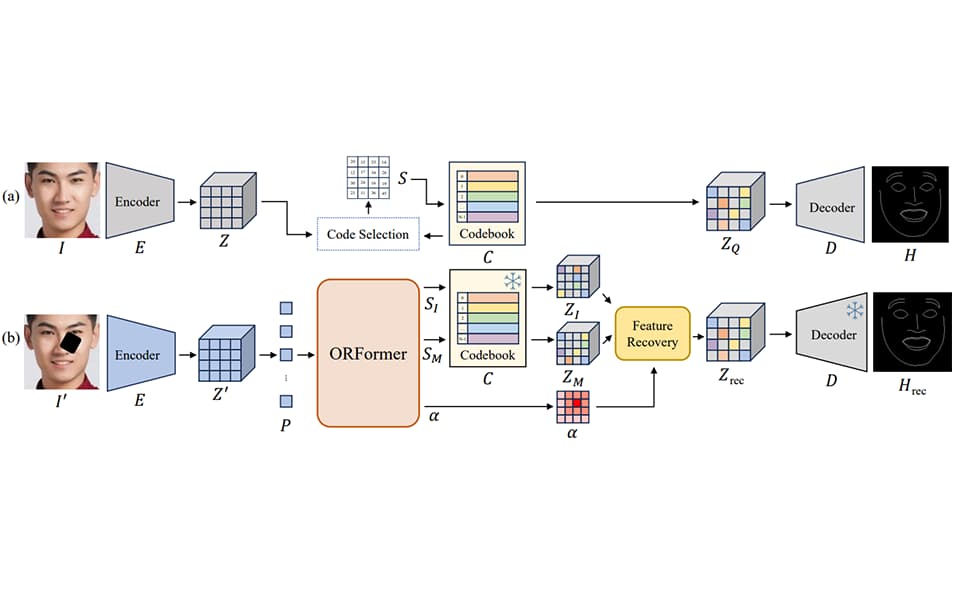
Jui-Che Chiang, Hou-Ning Hu, Bo-Syuan Hou, Chia-Yu Tseng, Yu-Lun Liu, Min-Hung Chen, Yen-Yu Lin WACV, 2025 (Oral Presentation) project page / arXiv / code A novel transformer-based method that can detect non-visible regions and recover their missing features from visible parts and performs favorably against the state of the arts on challenging datasets such as WFLW and COFW. |

|
Kuan-Hung Liu, Cheng-Kun Yang, Min-Hung Chen, Yu-Lun Liu, Yen-Yu Lin WACV, 2025 (Oral Presentation) project page / arXiv / code Experimental results demonstrate that CorrFill significantly enhances the performance of multiple baseline diffusion-based methods, including state-of-the-art approaches, by emphasizing faithfulness to the reference images. |
|
|
|

|
Chang-Han Yeh, Hau-Shiang Shiu, Chin-Yang Lin, Zhixiang Wang, Chi-Wei Hsiao, Ting-Hsuan Chen, Yu-Lun Liu arXiv, 2024 project page / arXiv / code / demo It is shown that this method not only achieves top performance in zero-shot video restoration but also significantly surpasses trained models in generalization across diverse datasets and extreme degradations. |
 
|
Chi-Wei Hsiao, Yu-Lun Liu, Cheng-Kun Yang, Sheng-Po Kuo, Yucheun Kevin Jou, Chia-Ping Chen NeurIPS, 2024 project page / paper / code This work proposes ReF-LDM, an adaptation of LDM designed to generate HQ face images conditioned on one LQ image and multiple HQ reference images, and designs a timestep-scaled identity loss, enabling the LDM-based model to focus on learning the discriminating features of human faces. |
 
|
Ning-Hsu Wang, Yu-Lun Liu NeurIPS, 2024 project page / arXiv / code / demo This work proposes a new depth estimation framework that utilizes unlabeled 360-degree data effectively and uses state-of-the-art perspective depth estimation models as teacher models to generate pseudo labels through a six-face cube projection technique, enabling efficient labeling of depth in 360-degree images. |

|
Ting-Hsuan Chen, Jiewen Chan, Hau-Shiang Shiu, Shih-Han Yen, Chang-Han Yeh, Yu-Lun Liu NeurIPS, 2024 project page / arXiv / results / code / video / demo A video editing framework, NaRCan, which integrates a hybrid deformation field and diffusion prior to generate high-quality natural canonical images to represent the input video and employs multi-layer perceptrons (MLPs) to capture local residual deformations, enhancing the model's ability to handle complex video dynamics. |

|
Shih-Wei Guo, Tsu-Ching Hsiao, Yu-Lun Liu, Chun-Yi Lee IROS, 2024 project page / arXiv / video A novel coarse-to-fine continuous pose diffusion method to enhance the precision of pick-and-place operations within robotic manipulation tasks and facilitates the accurate perception of object poses, which enables more precise object manipulation. |
|
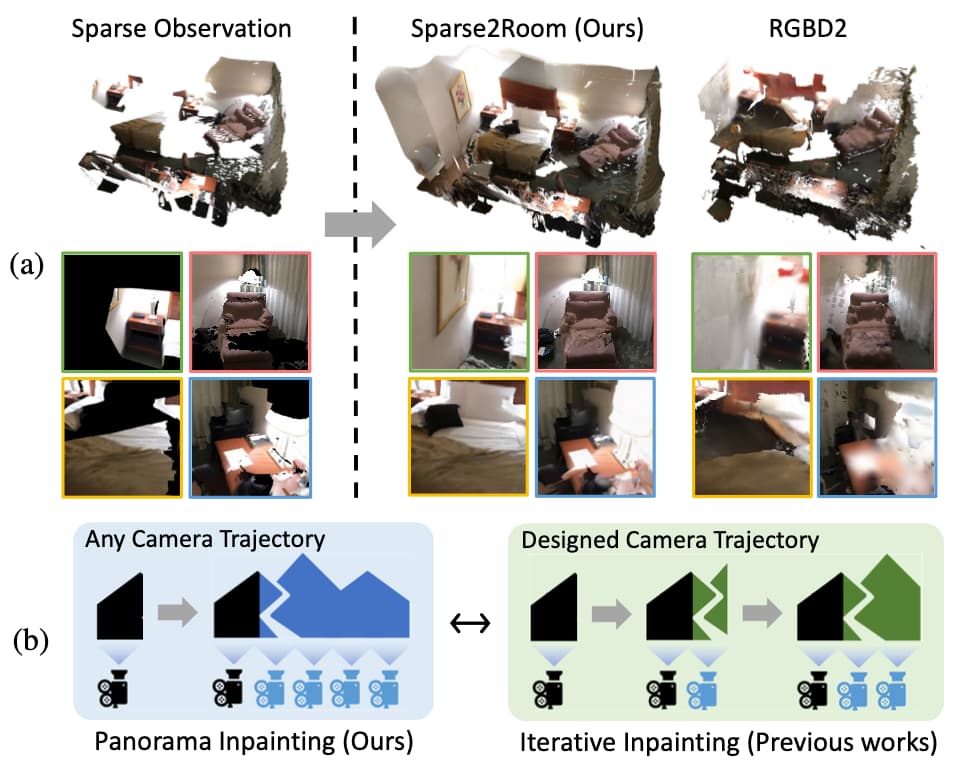
Ming-Feng Li, Yueh-Feng Ku, Hong-Xuan Yen, Chi Liu, Yu-Lun Liu, Albert Y. C. Chen, Cheng-Hao Kuo, Min Sun ECCV, 2024 project page / arXiv / code The proposed GenRC, an automated training-free pipeline to complete a room-scale 3D mesh with high-fidelity textures, outperforms state-of-the-art methods under most appearance and geometric metrics on ScanNet and ARKitScenes datasets, even though GenRC is not trained on these datasets nor using predefined camera trajectories. |
|
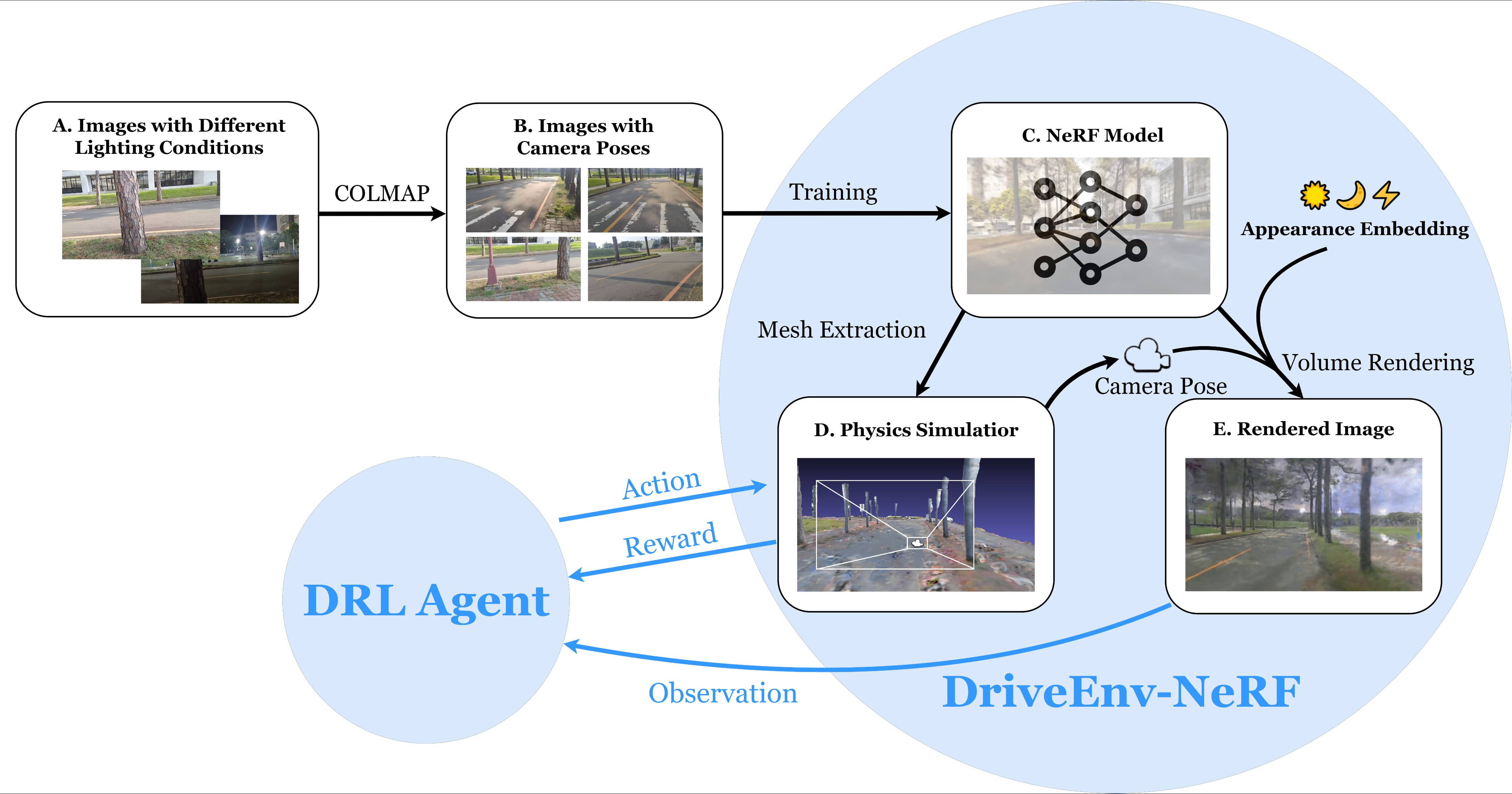
Mu-Yi Shen, Chia-Chi Hsu, Hao-Yu Hou, Yu-Chen Huang, Wei-Fang Sun, Chia-Che Chang, Yu-Lun Liu, Chun-Yi Lee ICRA RoboNerF Workshop, 2024 project page / video / arXiv / code The DriveEnv-NeRF framework, which leverages Neural Radiance Fields (NeRF) to enable the validation and faithful forecasting of the efficacy of autonomous driving agents in a targeted real-world scene, can serve as a training environment for autonomous driving agents under various lighting conditions. |
 
|
Zhixiang Wang, Baiang Li, Jian Wang, Yu-Lun Liu, Jinwei Gu, Yung-Yu Chuang, Shin'ichi Satoh SIGGRAPH, 2024 project page / arXiv / code [coming soon] / slides / supplement An innovative approach for image matting that redefines the traditional regression-based task as a generative modeling challenge and harnesses the capabilities of latent diffusion models, enriched with extensive pre-trained knowledge, to regularize the matting process. |

|
Chih-Hai Su*, Chih-Yao Hu*, Shr-Ruei Tsai*, Jie-Ying Lee*, Chin-Yang Lin, Yu-Lun Liu SIGGRAPH, 2024 project page / arXiv / code / video This paper presents a novel approach called BoostMVSNeRFs to enhance the rendering quality of MVS-based NeRFs in large-scale scenes, and identifies limitations in MVS-based NeRF methods, such as restricted viewport coverage and artifacts due to limited input views. |
|
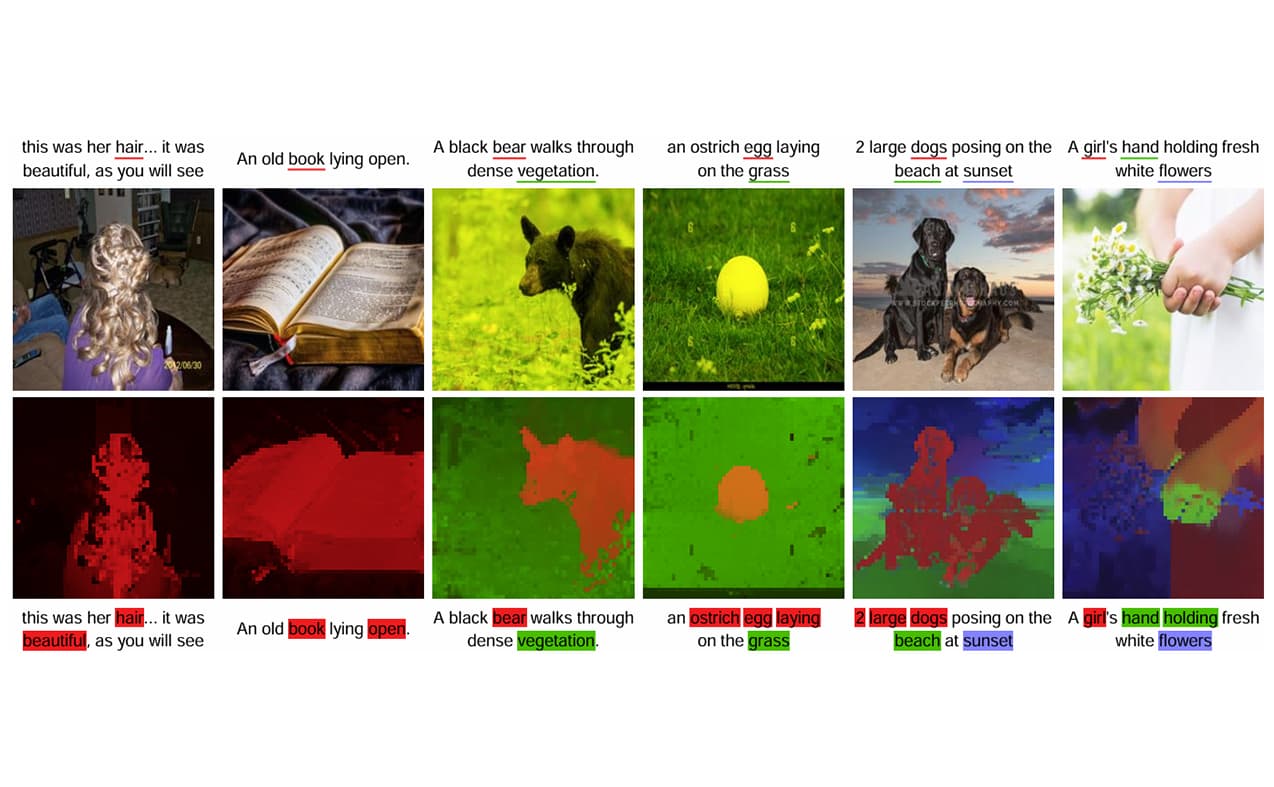
Ji-Jia Wu, Andy Chia-Hao Chang, Chieh-Yu Chuang, Chun-Pei Chen, Yu-Lun Liu, Min-Hung Chen, Hou-Ning Hu, Yung-Yu Chuang, Yen-Yu Lin CVPR, 2024 arXiv / code This paper addresses text-supervised semantic segmentation, aiming to learn a model capable of segmenting arbitrary visual concepts within images by using only imagetext pairs without dense annotations. |

|
Caoyuan Ma, Yu-Lun Liu, Zhixiang Wang, Wu Liu, Xinchen Liu, Zheng Wang CVPR, 2024 project page / arXiv / code This work reconstructs the previous HumanNeRF approach, combining explicit and implicit human representations with both general and specific mapping processes, and shows that explicit shape can filter the information used to fit implicit representation, and frozen general mapping combined with point-specific mapping can effectively avoid overfitting and improve pose generalization performance. |
|
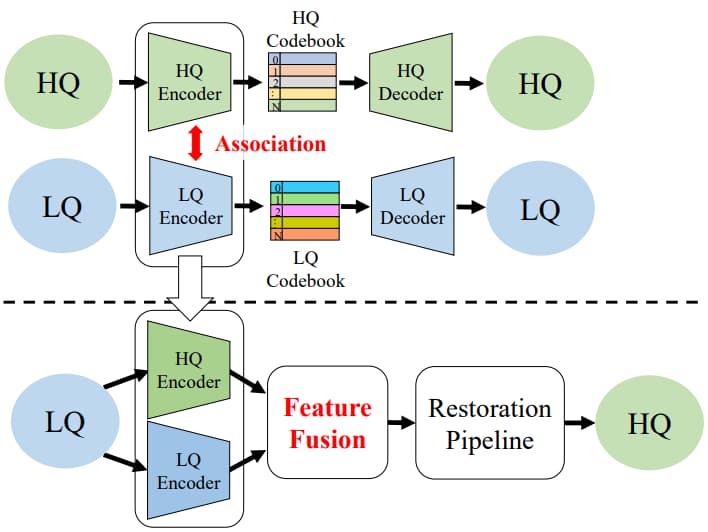
Yu-Ju Tsai, Yu-Lun Liu, Lu Qi, Kelvin C.K. Chan, Ming-Hsuan Yang ICLR, 2024 project page / arXiv This work proposes a novel dual-branch framework named DAEFR, which introduces an auxiliary LQ branch that extracts crucial information from the LQ inputs and incorporates association training to promote effective synergy between the two branches, enhancing code prediction and output quality. |

|
Zhixiang Wang, Yu-Lun Liu, Jia-Bin Huang, Shin'ichi Satoh, Sizhuo Ma, Guru Krishnan, Jian Wang IJCV, 2024 project page / arXiv This work proposes a simple yet effective method for correcting perspective distortions in a single close-up face using GAN inversion using a perspective-distorted input facial image, and develops starting from a short distance, optimization scheduling, reparametrizations, and geometric regularization. |
|
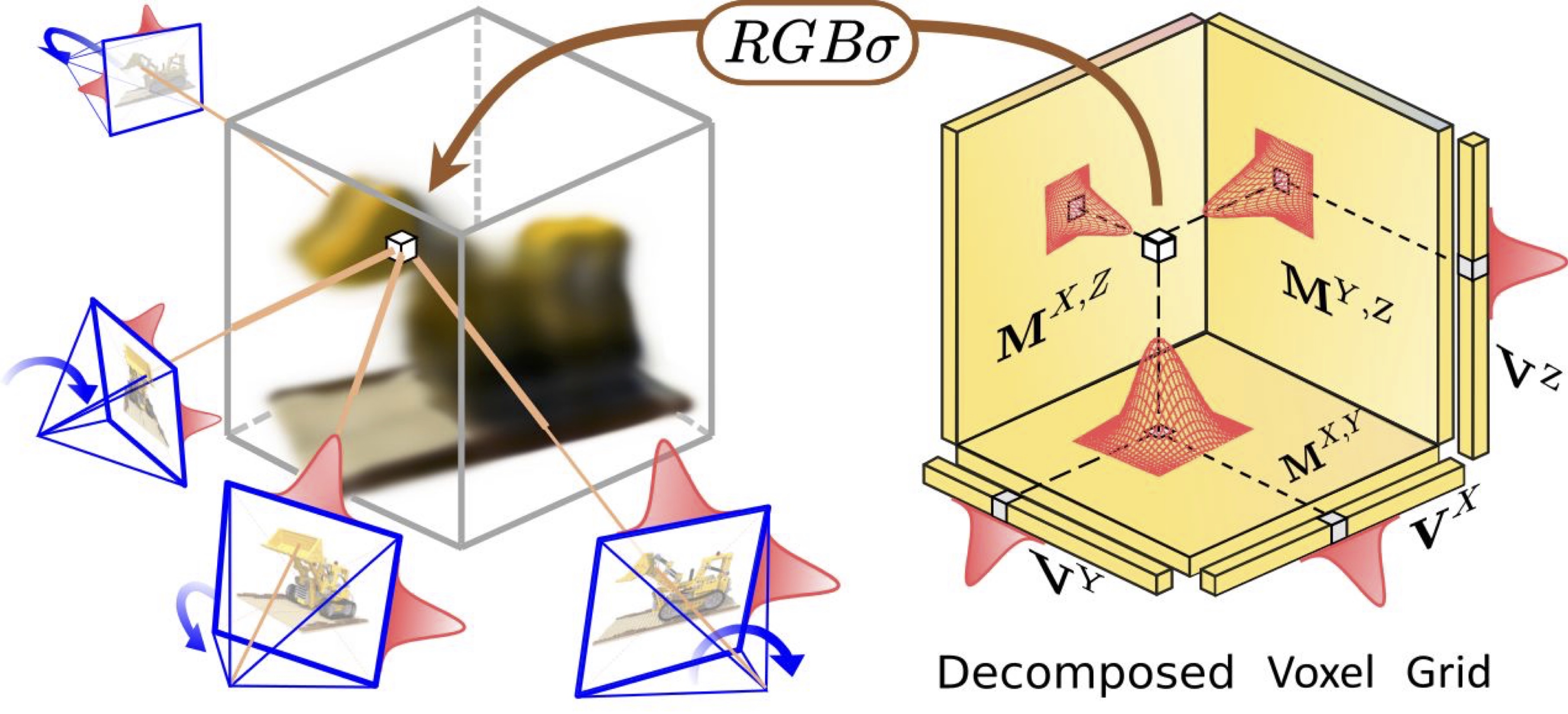
Bo-Yu Cheng, Wei-Chen Chiu, Yu-Lun Liu AAAI, 2024 project page / arXiv / code An algorithm that allows joint refinement of camera pose and scene geometry represented by decomposed low-rank tensor, using only 2D images as supervision is proposed, which achieves an equivalent effect to brute-force 3D convolution with only incurring little computational overhead. |
|
|
|
|
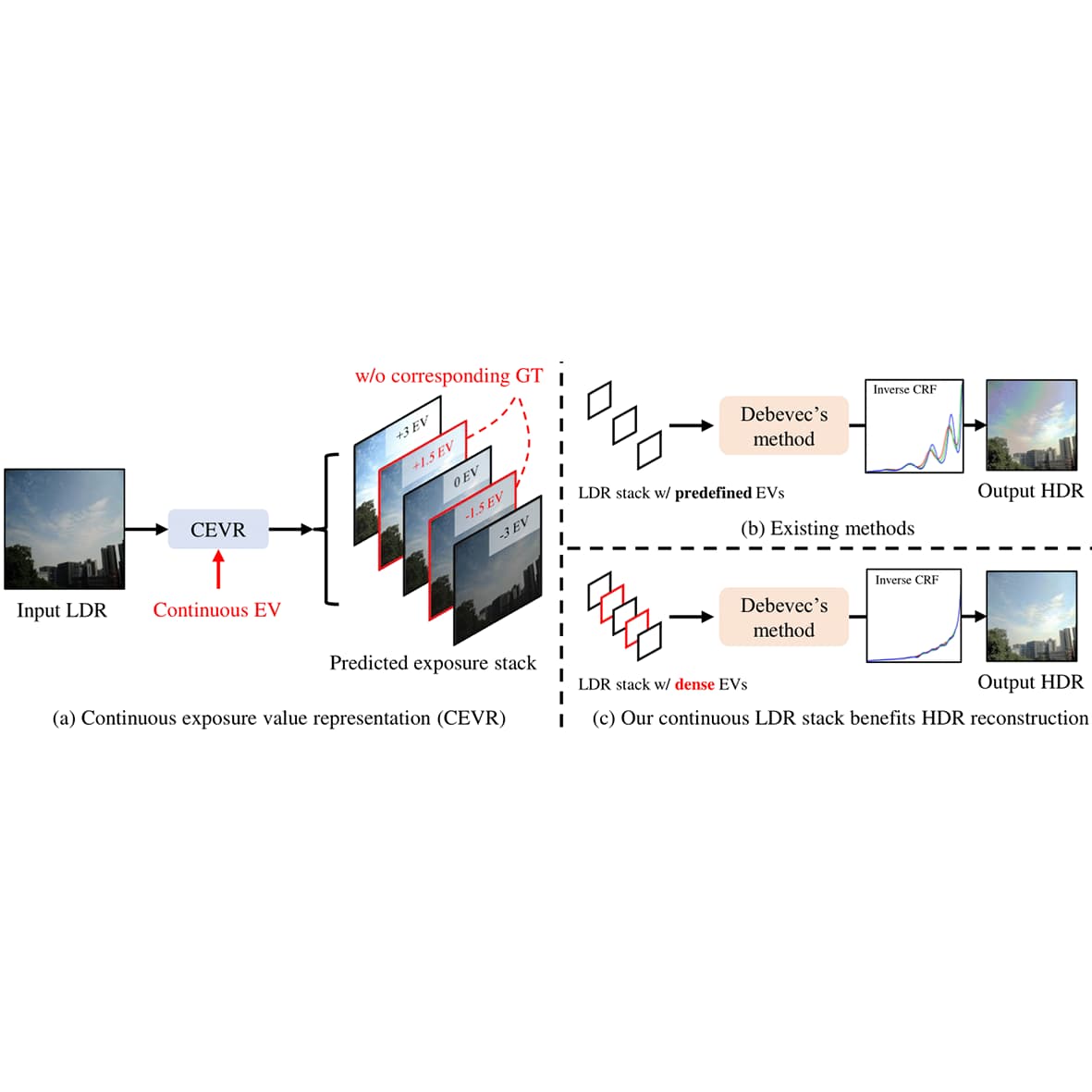
Su-Kai Chen, Hung-Lin Yen, Yu-Lun Liu, Min-Hung Chen, Hou-Ning Hu, Wen-Hsiao Peng, Yen-Yu Lin ICCV, 2023 project page / arXiv / code / video This work proposes the continuous exposure value representation (CEVR), which uses an implicit function to generate LDR images with arbitrary EVs, including those unseen during training, to improve HDR reconstruction. |
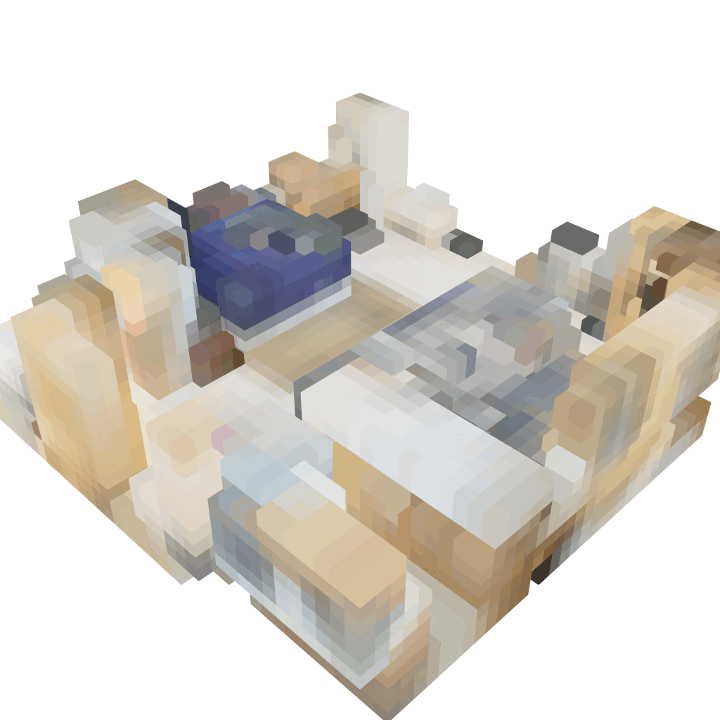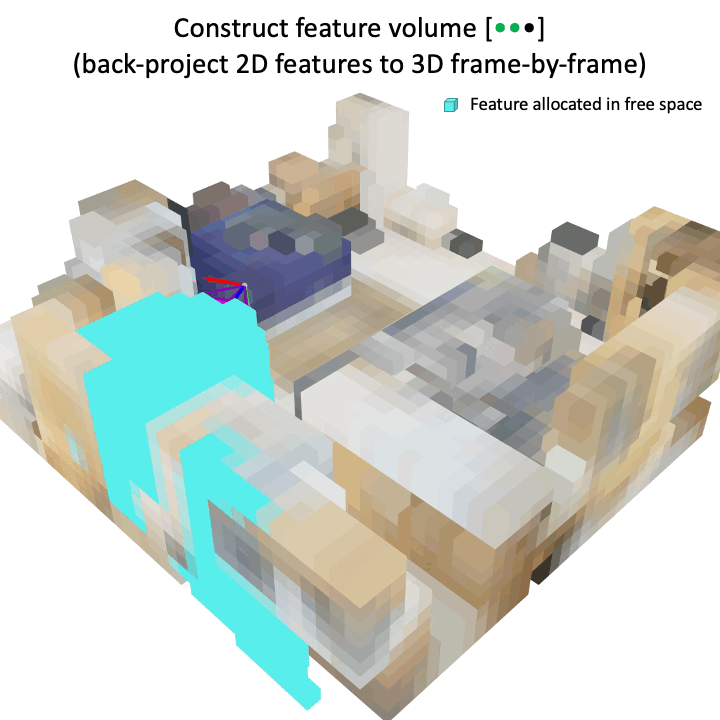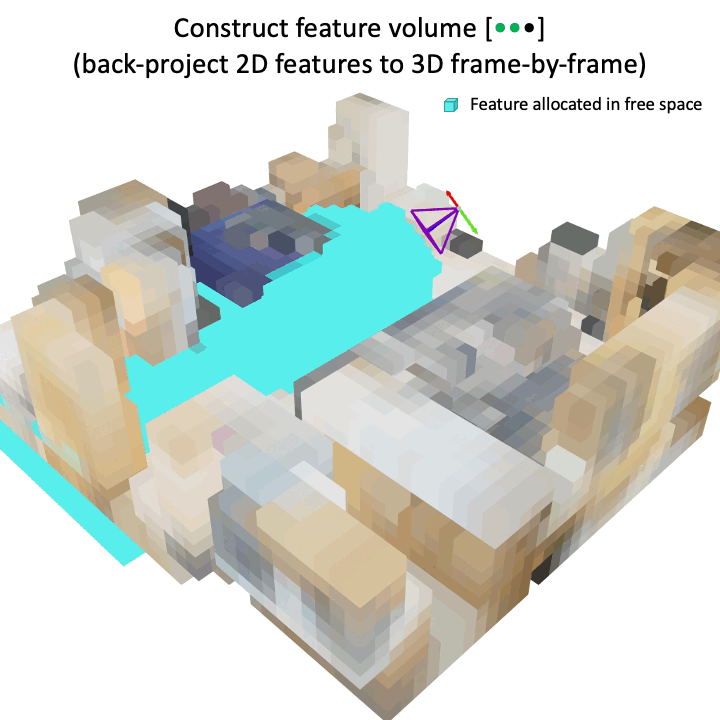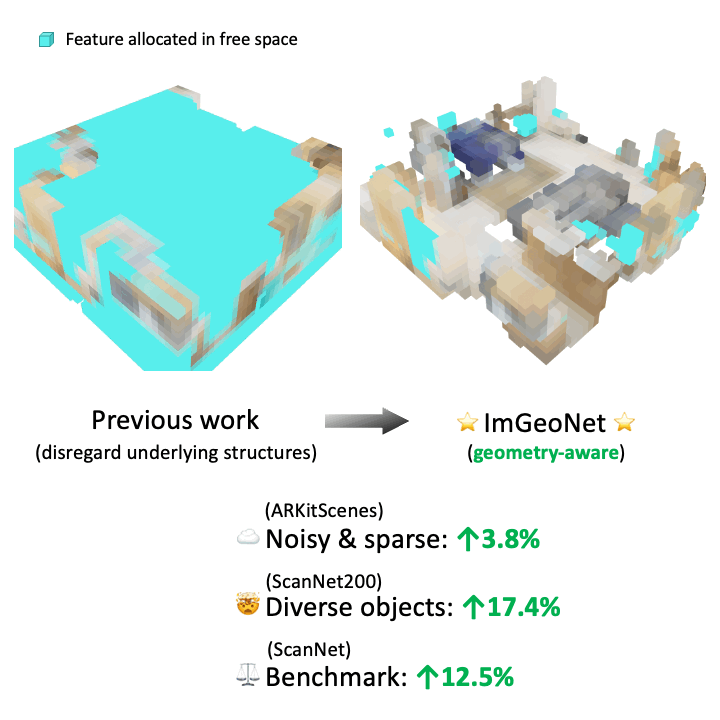 
|
Tao Tu, Shun-Po Chuang, Yu-Lun Liu, Cheng Sun, Ke Zhang, Donna Roy, Cheng-Hao Kuo, Min Sun ICCV, 2023 project page / arXiv The studies indicate that the proposed image-induced geometry-aware representation can enable image-based methods to attain superior detection accuracy than the seminal point cloud-based method, VoteNet, in two practical scenarios: (1) scenarios where point clouds are sparse and noisy, such as in ARKitScenes, and (2) scenarios involve diverse object classes, particularly classes of small objects, as in the case in ScanNet200. |

|
Andreas Meuleman, Yu-Lun Liu, Chen Gao, Jia-Bin Huang, Changil Kim, Min H. Kim, Johannes Kopf CVPR, 2023 project page / paper / code / video This work presents an algorithm for reconstructing the radiance field of a large-scale scene from a single casually captured video, and shows that progressive optimization significantly improves the robustness of the reconstruction. |

|
Yu-Lun Liu, Chen Gao, Andreas Meuleman, Hung-Yu Tseng, Ayush Saraf, Changil Kim, Yung-Yu Chuang, Johannes Kopf, Jia-Bin Huang CVPR, 2023 project page / arXiv / code / video This work addresses the robustness issue by jointly estimating the static and dynamic radiance fields along with the camera parameters (poses and focal length) and shows favorable performance over the state-of-the-art dynamic view synthesis methods. |
|
|
|

|
Chen-Hao Chao, Wei-Fang Sun, Bo-Wun Cheng, Yi-Chen Lo, Chia-Che Chang, Yu-Lun Liu, Yu-Lin Chang, Chia-Ping Chen, Chun-Yi Lee ICLR, 2022 arXiv / OpenReview This work forms a novel training objective, called Denoising Likelihood Score Matching (DLSM) loss, for the classifier to match the gradients of the true log likelihood density, and concludes that the conditional scores can be accurately modeled, and the effect of the score mismatch issue is alleviated. |
|
|
|

|
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang TPAMI, 2021 project page / arXiv / code / demo / video This work alternate between estimating dense optical flow fields of the two layers and reconstructing each layer from the flow-warped images via a deep convolutional neural network, facilitates accommodating potential errors in the flow estimation and brittle assumptions, such as brightness consistency. |
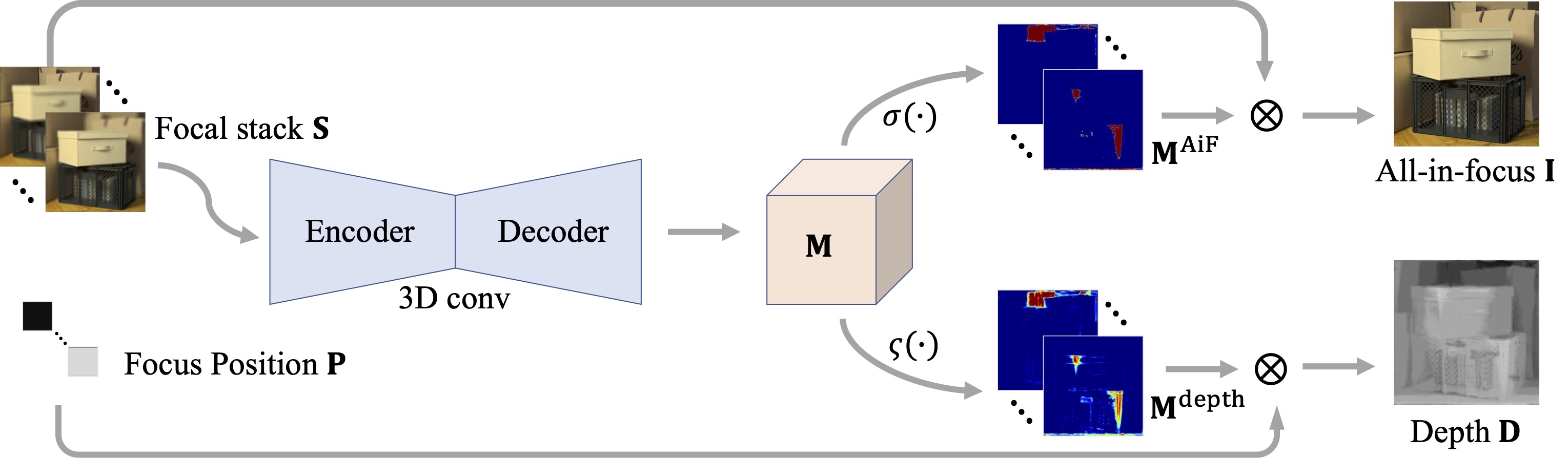
|
Ning-Hsu Wang, Ren Wang, Yu-Lun Liu, Yu-Hao Huang, Yu-Lin Chang, Chia-Ping Chen, Kevin Jou ICCV, 2021 project page / arXiv / code This paper proposes a method to estimate not only a depth map but an AiF image from a set of images with different focus positions (known as a focal stack), and shows that this method outperforms the state-of-the-art methods both quantitatively and qualitatively, and also has higher efficiency in inference time. |

|
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang ICCV, 2021 project page / arXiv / poster / slides / code / demo / video / Two minute video This work presents a frame synthesis algorithm to achieve full-frame video stabilization that first estimate dense warp fields from neighboring frames and then synthesize the stabilized frame by fusing the warped contents. |
|
|
|

|
Chien-Chuan Su, Ren Wang, Hung-Jin Lin, Yu-Lun Liu, Chia-Ping Chen, Yu-Lin Chang, Soo-Chang Pei ICPR, 2020 arXiv This paper proposes a learning-based multimodal tone-mapping method, which not only achieves excellent visual quality but also explores the style diversity and shows that the proposed method performs favorably against state-of-the-art tone-Mapping algorithms both quantitatively and qualitatively. |

|
Ke-Chi Chang, Ren Wang, Hung-Jin Lin, Yu-Lun Liu, Chia-Ping Chen, Yu-Lin Chang, Hwann-Tzong Chen ECCV, 2020 project page / arXiv / code A data-driven approach, where a generative noise model is learned from real-world noise, which is camera-aware and quantitatively and qualitatively outperforms existing statistical noise models and learning-based methods. |

|
Yu-Lun Liu*, Wei-Sheng Lai*, Yu-Sheng Chen, Yi-Lung Kao, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang CVPR, 2020 project page / arXiv / poster / slides / code / demo / 1-minute video This work model the HDR-to-LDR image formation pipeline as the dynamic range clipping, non-linear mapping from a camera response function, and quantization, and proposes to learn three specialized CNNs to reverse these steps. |

|
Yu-Lun Liu, Wei-Sheng Lai, Ming-Hsuan Yang, Yung-Yu Chuang, Jia-Bin Huang CVPR, 2020 project page / arXiv / poster / slides / code / demo / 1-minute video / video / New Scientists The method leverages the motion differences between the background and the obstructing elements to recover both layers and alternate between estimating dense optical flow fields of the two layers and reconstructing each layer from the flow-warped images via a deep convolutional neural network. |

|
Yu-Ju Tsai*, Yu-Lun Liu*, Yung-Yu Chuang, Ming Ouhyoung AAAI, 2020 paper / code / benchmark A novel deep network for estimating depth maps from a light field image that generates an attention map indicating the importance of each view and its potential for contributing to accurate depth estimation and enforce symmetry in the attention map to improve accuracy. |
|
|
|
|
Yu-Lun Liu, Yi-Tung Liao, Yen-Yu Lin, Yung-Yu Chuang AAAI, 2019 (Oral Presentation) project page / paper / poster / slides / code / video A new loss term, the cycle consistency loss, which can better utilize the training data to not only enhance the interpolation results, but also maintain the performance better with less training data is introduced. |
|
|
|

|
Yu-Lun Liu, Hsueh-Ming Hang APSIPA, 2014 paper This paper focuses on creating a global background model of a video sequence using the depth maps together with the RGB pictures, and develops a recursive algorithm that iterates between the depth map and color pictures. |
|
|
|

|
Du-Hsiu Li, Hsueh-Ming Hang, Yu-Lun Liu PCS, 2013 paper A backward warping process is proposed to replace the forward warped process, and the artifacts (particularly the ones produced by quantization) are significantly reduced, so the subjective quality of the synthesized virtual view images is thus much improved. |
|
|
 |
International Program Committee, Pacific Graphics 2025
Technical Papers Conflict of Interest Coordinator, SIGGRAPH Asia 2025 Publication Chair, ACCV 2024 Area Chair: NeurIPS 2025, ACCV 2026, MVA 2025, NeurIPS 2026 Conference Reviewer: CVPR, ICCV, ECCV, NeurIPS, ICLR, ICML, SIGGRAPH, SIGGRAPH Asia, AAAI, IJCAI Journal Reviewer: TPAMI, IJCV, TIP, TOG |
|
|
 |
NYCU - Fall 2025 (Instructor) |
 |
NYCU - Spring 2023, Fall 2023, Fall 2024, Fall 2025 (Instructor) |
 |
NYCU - Spring 2024, Spring 2025, Spring 2026 (Instructor) |
 |
NCTU - Spring 2013 (Teaching Assistant) |
|
My research is made possible by the generous support of the following organizations.
|

{kind=link}
{kind=link}
{kind=link}
|
Stolen from Jon Barron's website.
|